 Inspired by Donald Knuth's 1959 "Super-random" number generator that didn't work (see Page 5), I created my own generator which I think does work, but only by brute force and theft of other algorithms (it also has poor performance).
Inspired by Donald Knuth's 1959 "Super-random" number generator that didn't work (see Page 5), I created my own generator which I think does work, but only by brute force and theft of other algorithms (it also has poor performance).
Monday, November 21, 2022
The Stupid Random Number Generator

Tuesday, October 18, 2022
CRC vs Hash Algorithms
 Before the System.IO.Hashing namespace was introduced in late 2021, the .NET FCL (Framework Class Library) did not provide any classes for error detection or hashing.
Before the System.IO.Hashing namespace was introduced in late 2021, the .NET FCL (Framework Class Library) did not provide any classes for error detection or hashing.
For error detection you would have to find some code for one of the CRC algorithms and paste it into your codebase. Some developers may find that objectionable.
For hashing you could use the built-in MD5 class, but it produces a 16-byte cryptographic hash which may be overkill for typical business apps that just want to generate hash keys for database rows or dictionaries. Otherwise you would have to paste-in some code that implements a popular non-crypto hash algorithm such as FNV, Murmur, and many others. Web searches reveal many algorithms that produce 32-bit or 64-bit hashes, which unfortunately means there is too much choice and you have to make a decision.
For the last 20 years, I followed these rough rules:
- For signing data I use an MD5 hash. The 16 bytes can conveniently be manipulated in a Guid. MD5 is old and regarded as cryptographically "broken", but I'm happy to use it to create the internal signature of the contents of a database row, for example.
- For hashing small numbers of strings in non-persistent dictionaries I would use FNV-1a because it's only a few lines of code and it's well researched.
- For all other persistent hashes I preferred to use CRC-64 (ECMA 182), via code I stole decades ago and placed in a shared library. 64-bit hashes are collision resistant for several million items, but don't use 32-bit hashes because they are too short as described in Birthday Attack.
With the arrival of the System.IO.Hashing namespace we now have classes specifically designed for error checking (the CRC classes) and for hashing (the XxHash classes). You can throw away your borrowed or hand-written equivalent code.
The arrival of the classes also made me realise that I've been a naughty developer because I have historically been using an error detecting algorithm as a hash algorithm. The distinction is important...
👉 Error detecting codes like those created by CRC are specifically designed to detect common types of accidental changes to digital data (as described in the Wikipedia article). I can't find any evidence that CRC was also designed to produce good hash codes, but luckily it does. My HashStrings app and other tests shows that CRC produces widely distributed and collision resistant output codes. This reassures me that I haven't been making a gross mistake in using CRC for hashing over the last 20 years.
👉 A hash algorithm is specifically designed to convert arbitrary amounts of input data into a small fixed-size value called the hash, digest, or signature. It is desirable that the algorithm be sensitive so that small changes to the input produce completely different hash outputs, and that the hashes be widely distributed. The new XxHash classes claim to satisfy all of those requirements.
In the future I will drop using CRC or FNV-1a for hashing and I will switch to XxHash for all hashing.
I will continue to use MD5 for making internal data signatures that need to be more secure than a hash.
Further reading:
Thursday, August 25, 2022
PRNG Relative Performance
I was wondering about the relative speed of different Pseudo-Random Number Generator (PRNG) algorithms. I wrote a DOS command with methods annotated by BenchmarkDotNet attributes and gave it a run. This chart shows the relative speed of the algorithms running in a tight loop to generate 500K Int32 values. The result of each PRNG iteration was converted to an Int32 (if it wasn't one already) and added to a global Int32 so that the iterations wouldn't be optimised to nothing. The single add in each iteration should not skew the results.
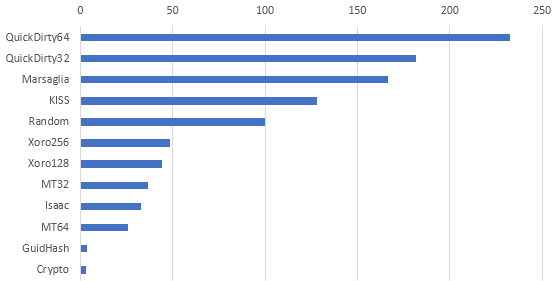
Most of the algorithms are well-known and many of them are described in my Orthogonal.Common.Basic library documentation. Some observations:
- I expected the Quick 32-bit to win because it's a one-liner with one add and one truncated multiply, but the Quick 64-bit beat it for some reason.
- The Quick 64-bit is also a one-liner, but the 32-bit halves are xor'd together (which makes it a two-liner) and cast to an Int32, and despite that overhead it still wins. I suspect that this two-liner is one of the fastest reasonably good amateur PRNGs you can use.
- The Marsaglia and KISS algorithms beat the .NET Random, but they are both rather old and inferior by modern standards and are only included for historical comparison.
- The .NET Random class beats all other modern algorithms by a wide margin, even ones that are regarded as lightweight and efficient. This is quite surprising, and it might be due to some implementation details of the Knuth Subtractive algorithm that I'm not aware of. More research is needed to explain this.
- The modern Xoro algorithms are good performers, which is lucky because they're quite popular and one of them is replacing the internals of the latest .NET Random class (for more information see Random Numbers).
- I was shocked to see Guid.GetHashCode perform so poorly. It's suspicious that Guid hashes and the crypto-strong byte generator run at nearly identical speeds. This hints that the Guid uses the crypto PRNG internally, which is a question discussed in my blog post titled Guid Constant Bits.
 Zip of the Visual Studio 2022 solution
Zip of the Visual Studio 2022 solutionSunday, July 24, 2022
Phone number as sum of powers
One of Dave Plummer's videos titled Top 50 Worst Computer Dialogs skims through a selection of different hilariously absurd and impractical web controls for picking dates, phone numbers, audio volume, etc.
At the 10:53 mark he shows a control where you must specify your phone number as the sum of three powers.

This intrigued me. I guessed that numbers representable in the desired form might be rather sparse up in the range of my mobile phone number which has this form (0)419XXXXXX. I wondered how sparse they were and if my phone number was one of the lucky ones. There were a few ways of tackling this question.
Random
Chose random integers for the six values in the range 1 to (say) 12 and see if a match results. This may sound stupid, but some C# script code in LINQPad can run this loop about 7 million times per second and it will quickly find a match if one exists. My phone number did not match using this technique.
Exhaustive
Loop over all combinations of the six variables to find a match. This is also stupid, because it's not only exhaustive, it's exhausting and many duplicates will occur, but I ignored that and went ahead anyway.
My C# script searched about 7 million combinations in only 10 seconds with powers up to 16 and did not find a phone number match. At this point I had proof that my phone number was not expressible in the required form.
Mathematica
I was wondering which numbers in the 9-digit range of my phone number were expressible as the sum of three powers, so I fired-up Mathematica and ran a search over distinct combinations of the six variables and tallied which numbers were expressible and in how many ways. For powers up to 16 it took about 20 seconds to produce these results in the range of my phone number:
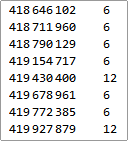
As I suspected, the expressible numbers are actually quite sparse up in this range, but it's interesting to see that certain lucky numbers can be expressed in 6 or 12 distinct ways, probably because of simple relations such as 46 == 212.
Sunday, July 17, 2022
WinForms RadioButton Binding
 Last week I had to write demo program using Windows Forms, which was a mind-trip into the past because I migrated to using WPF for all desktop apps since 2010. As an academic exercise I tried to use data binding of the UI controls to properties of a controller class. For me, Windows Forms binding works acceptably well, but it has never felt like a first-class citizen in comparison to WPF where it's deeply integrated into the framework.
Last week I had to write demo program using Windows Forms, which was a mind-trip into the past because I migrated to using WPF for all desktop apps since 2010. As an academic exercise I tried to use data binding of the UI controls to properties of a controller class. For me, Windows Forms binding works acceptably well, but it has never felt like a first-class citizen in comparison to WPF where it's deeply integrated into the framework.
I stumbled upon an old problem that has bugged me for almost 20 years ... how to bind a group of RadioButton controls to an Enum property that represents the choices. With a fresh mind I finally solved the problem, and I've created a small sample project to preserve the code for posterity. See:
DevOps Repository - RadioBindingSample
I think it's important to point out that the original Windows Forms demo program was eventually abandoned and most of the code was migrated into a nearly identical WPF program. The Forms demo was proceeding reasonably well until more complex binding was required, and I was creating custom binding logic that was mimicking what WPF already has built-in. I had reached the same decision tipping point I had previously reached around 2009 when I realised that the powerful binding techniques available in WPF outweigh any other justifications for continuing to use Windows Forms.
Most controls in the Windows Forms namespace derive from Control which has a DataBindings property which contains a collection of binding rules. Some controls such as ToolStripItem derive from Component and do not support binding, and that's when custom binding code is required and things can get messy and convoluted. This is around the tipping point to move to WPF.
Wednesday, June 15, 2022
C++ Stupidity and Delusion

I recently returned to writing C++ after a 17-year gap and I have concluded that C++ has become the stupidest language in contemporary common use and fans of the language are living in some form of mass delusional insanity.
When I wrote C++ from about 1993 to 2003 it was basically "C with Classes" and it claimed to guide you away from C spaghetti code into the superior and trendy OOP world of software development. That claim was generally fulfilled, but I often found myself creating classes that didn't need to exist, and there was always the risk of creating "spaghetti classes". It's worth noting that opinions of OOP have not aged well and web searches for "OOP sucks" or "OOP is bad" will produce some withering criticism.
Upon returning to C++ after a long absence, I am shocked and angered by what I have found. Several major enhancements over the decades have added so many features to the language with so much syntax that it looks like an unstoppable academic research project that went out of control and became a joke. And ironically, the community using the language don't seem to realise they're part of the joke.
I have recently watched lots of videos about C++, and the ones taken at conventions are the most worrying because people like Bjarne and Herb come on stage and are cheered like heroes by an audience that uncritically drools over upcoming C++ features that are discussed in great detail. What makes me both angry and incredulous is that most of the recently added and upcoming C++ features are either making the language more and more complex, or they are features that have been built-in to other popular programming languages for a lifetime.
Languages like Java and C# have had parallelism, reflection, networking support, UI designers, modules and much more for decades, but here we are in the far distant science fiction future of 2022 and the C++ committees are only now proposing to add these features that are vital for software development. C++ is so far behind the ecosystem of other modern languages that it's another joke they don't get, and they continue to blindly cram the language with more libraries and syntax stolen from other languages to try and keep it up to date with its modern contemporaries.
Writing C++ is so staggeringly complex that I need cheat-sheets always open, and sometimes I must Google search on how to write every line of code correctly. As a result, my C++ coding speed often hovers at around 10 to 20 lines of code per hour. It took me 3 solid days of hair-tearing suffering to find a library that made REST web service calls, compile it, and make it work. A colleague took two days to get a zip library working and at one point he said, "lucky I don't live near a cliff". Both of those tasks could be coded in a few lines of a modern language in less than a minute.
Have a look at the Working Draft or the C++ Reference to get a feel for the astonishing complexity of C++. There are countless videos online as well that discuss all of the frightening traps and tricks of C++ coding and how to use the huge list of language features correctly (see Jason Turner's videos). The complexity of C++ creates a huge learning hurdle for even the most skilled developer who could require up to a year of intensive experience to become an expert.
C++ doesn't have a public library system (like packages or crates), the error messages are beyond mortal comprehension, you can't tell which language features are "safe" to use on your platform, everyone argues about the best coding patterns, and most sample code won't compile. In my words (which can often be heard shouted from the other end of the house) … "Everything f***ing doesn't work!!". In C++, everything is as ridiculously cryptic and difficult as it can possibly be. I often joke that writing C++ is harder than building an atomic clock.
The C++ fanbase brags about how widespread its usage is and how many diverse and performance critical systems depend upon it, but I think this is just a historical hangover because it grew out of the popularity of C back when there were no alternatives. I saw C++ become trendy and cool back in the 1990s and it developed a kind of aura or mystique about it, mainly because it was so complex and intimidating to average developers of the time. If you told people you were writing C++ you could often see reverent "Oh you're a real programmer" looks on their faces. C++ just happened to arrive at the right time to fill a void and I think the C++ community is still living in the 1990s.
The other C++ brag is about how it is "close to the metal" and can produce apps with unequalled performance. C++ continues to ride high on its performance claims, but it's become an urban legend that's no longer a compelling argument. Recent research by my own colleagues with nearly identical cross-tabulation libraries written in C# and C++ finds that the C++ library only performs slightly better when very large amounts of data are being processed, which results in very large in-memory tables.
Even if optimised C++ does produce more performant native binaries, who needs that? Typical business apps are not performance critical and writing them quickly in C#, Swift, Java or Python will save immeasurable money and suffering. Maybe C++ is vital in creating database engines, embedded systems or niche scientific applications, but in the last 15 years I have never met a single living developer who works in any of those industries and needs to expend enormous effort to squeeze out top performance. You would have to be out of your mind to consider using C++ to write a desktop app, or a background service, or a web service for business use in 2022. If you asked me to write a Windows desktop app or web service in C++, it would take at least 20 times longer than writing it in C#.
In summary, I will reiterate without embarrassment that C++ is the most utterly stupid programming language in popular use, it's getting stupider, and its community is living in a world of delusion.
C++ should be deprecated now and go into maintenance mode.
One would normally recommend that all development effort be channelled into designing a modern replacement for C++, but what's the point, because robust and respected alternatives are already available.
Bjarne often talks about the "ideal C++" and how it will never stop evolving. By the time it reaches his "ideal" it will be extinct.
Sunday, May 29, 2022
NuGet include native DLL
July Update : The advice in this post works for typical NuGet consumption, such as adding a package to
a Visual Studio solution. However, it was found that #r "NuGet: XXX" in a csx script file does
not cause the native DLLs in the package to be downloaded. At a guess, the custom build targets are not processed outside of the Visual Studio process.
For most people this script problem wouldn't be a concern, but unfortunately, our package was designed to be used with equal ease by csx scripting and Visual Studio projects. The only answer was to rewrite the C++ native DLL in C# so that the problem this post addresses simply went away. Removing the native DLL was like having a headache cured.
The original post remains here, just in case it might be useful to other developers.
I had to create a NuGet package which included a native DLL written in C++. Utility functions in the native DLL are called from C# using standard Interop techniques. The projects consuming the package may be either the traditional Framework format or the newer Sdk format. The vital requirement is that the native DLL is copied to the build output folder in the same way as managed DLLs.
The documentation on packaging and delivering extra files via NuGet is vague and confusing, and web searches produce hundreds of equally confusing and often contradictory arguments on the subject. After weeks of part-time research and suffering I finally stumbled upon the answer by merging hints from a variety of sources.
Note that a group like the following in the source package project will produce the desired behaviour when consumed by an Sdk project, but has no effect in a Framework project.
<ItemGroup>
<None Include="{Path to the native DLL}">
<CopyToOutputDirectory>Always</CopyToOutputDirectory>
<Pack>True</Pack>
<PackagePath>contentFiles\any\any</PackagePath>
<PackageCopyToOutput>true</PackageCopyToOutput>
</None>
</ItemGroup>
I will pretend that the source project name and namespace is Acme.Widget.
To get the desired behaviour in both types of consuming projects. Add a file named Acme.Widget.targets to the source project with action None and Do not copy.
<Project xmlns="http://schemas.microsoft.com/developer/msbuild/2003">
<ItemGroup>
<None Include="$(MSBuildThisFileDirectory)\native-utility.dll">
<Link>native-utility.dll</Link>
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
</None>
</ItemGroup>
</Project>
This targets file will be inserted into the receiving project's build processing where it will extract the native DLL from the package and copy it to the build output folder.
Add the following items to the source project.
<ItemGroup>
<None Include="Acme.Widgets.targets">
<CopyToOutputDirectory>Never</CopyToOutputDirectory>
<Pack>True</Pack>
<PackagePath>build\</PackagePath>
<PackageCopyToOutput>true</PackageCopyToOutput>
</None>
</ItemGroup>
<ItemGroup>
<None Include="{path to native-utility.dll}" Link="native-utility.dll">
<CopyToOutputDirectory>Always</CopyToOutputDirectory>
<Pack>True</Pack>
<PackagePath>build\</PackagePath>
<PackageCopyToOutput>true</PackageCopyToOutput>
</None>
</ItemGroup>
The first item places the targets file into the special build folder in the package. The NuGet system recognises that the package wants to modify the receiving project's build processing.
The second item links the native DLL into the source project so it can be used normally for development and testing. It also adds it to the build folder in the package.
In summary, the trick is to put a targets file and the native DLL into the build folder in the package. When a project receives the package, the targets file is inserted into the build process and it copies the native DLL to the build output folder. This creates the illusion that the native DLL behaves just like a normal managed DLL.
I remain suspicious that my instructions can be simplified or follow conventions that are currently unknown to me. The whole process seems too complicated. Expert feedback would be welcome.
Sunday, May 8, 2022
Because it is being used by another process
I wanted to scan the contents of log files, but many of them failed to open because of:
The process cannot access the file 'filename' because it is being used by another process.
This is a pretty pedestrian error that most people will see in their lives and probably accept and ignore. I was less happy though because I could open the files in Notepad but my simple use of new StreamReader(filename) was failing. I guessed there would be some combination of classes and parameters that would let me read the files, and after trying several combinations I found this works:
using (var stream = new FileStream(filename, FileMode.Open, FileAccess.Read, FileShare.ReadWrite))
using (var reader = new StreamReader(stream))
{
string line = reader.ReadLine();
}
The FileShare values are described in the Win32 CreateFile documentation. The values are published unchanged as a .NET enum.
You are still at the mercy of how the other process has opened the file you are trying to read. You can open a file so that it is deliberately inaccessible to others.
Saturday, April 30, 2022
Entity Framework 6 and HierarchyId
This post is referring to the legacy Entity Framework EDMX file. I have read somewhere (I forget where) that the problem described below is not applicable to EF Core where the model is managed in a completely different way, either by code-first or scaffolding from an existing database.
If you create an Entity Framework 6 EDMX (data model) which contains tables with columns of type hierarchyid then you will get some warnings and the table will arrive in the designer with the offending columns removed. However, you can define and process those types of columns in a strongly-typed manner.
Add NuGet package Microsoft.SqlServer.Types to your project.
Create a partial class that contains the missing hierarchical columns, like this example:
using Microsoft.SqlServer.Types;
:
partial class SomeTable
{
public SqlHierarchyId SomeNode { get; set; }
}
Unfortunately you can't use LINQ queries on the tables to process rows containing these types of columns. Write some helper methods that use traditional ADO.NET to execute a reader over the table and cast the row-column value to a .NET type like this:
var someNode = (SqlHierarchyId)reader.GetValue(1); var otherNode = reader.IsDBNull(2) ? SqlHierarchyId.Null : (SqlHierarchyId)reader.GetValue(2)
Note how the second sample line deals with a nullable hierarchyid column.
Thursday, April 21, 2022
Visual Studio 2022 target 4.5
My laptop which has only had Visual Studio 2022 installed and has no history of any other versions being installed will not load projects targeting .NET Framework 4.5. It suggests a download, but no suitable files are available from the Microsoft download pages any more.
Thomas Levesque's instructions for a fix seem dangerous, but after several futile experiments I found that his steps work:
Download the Nuget package Microsoft.NETFramework.ReferenceAssemblies.net45
Rename the following folder (to keep a backup) and replace it with the v4.5 folder unzipped from the NuGet package.
C:\Program Files (x86)\Reference Assemblies\Microsoft\Framework\.NETFramework\v4.5
Thereafter VS2022 can open, build and run 4.5 projects. You'll need suitable account permission to rename and replace the folders.
Wednesday, March 30, 2022
Set specific directory access controls
I had to create a directory with was only accessible to a specific Windows account and no other accounts, not even Administrators or SYSTEM. This was needed to isolate the important directory and its files from accidental (or malicious) access by any process other than the single service that used them.
The .NET Framework has managed wrapper classes over most of the Windows security API, but to the developer who only tampers with security occasionally, the classes can be really confusing. The relationships between account names, SIDs, ACLs, ACEs, inheritance, propagation, etc can be hard to remember and untangle.
As a reminder to myself and others, here is skeleton code that isolates a directory by removing all existing account access, disabling inheritance from the parent folder, then adding access to a specific account.
In my example I use the built-in NETWORK SERVICE account as the one to have access, but that can be replaced with different account(s).
var dir = new DirectoryInfo(@"D:\temp\TestDir");
var sid = new SecurityIdentifier(WellKnownSidType.NetworkServiceSid, null);
NTAccount acc = (NTAccount)sid.Translate(typeof(NTAccount));
var rule1 = new FileSystemAccessRule(
acc,
FileSystemRights.Modify,
InheritanceFlags.ContainerInherit | InheritanceFlags.ObjectInherit,
PropagationFlags.None,
AccessControlType.Allow);
var dsec = new DirectorySecurity();
dsec.SetAccessRuleProtection(true, false);
dsec.AddAccessRule(rule1);
dir.SetAccessControl(dsec);
A bit of a trick is the usage of the SetAccessRuleProtection call to disable inheritance from parent directories. If you dump a DirectorySecurity object you will see it corresponds to the DACL, and that's where inheritance is defined.
For a similar exercise related to the Registry, see the post titled Registry Secrets and Permissions.
Saturday, March 12, 2022
Silverlight death and funeral
The light that burns twice as bright burns half as long - and you have burned so very, very brightly, Silverlight.
With apologies to Blade Runner, I feel the quote is appropriate. Silverlight version 2 to 5 lived from 2007 to 2012 when Microsoft very quietly announced that development had ceased and end-of-life was scheduled for October 2021. That's a very short lifetime, even when measured in software platform years.
The .NET developer community was angered and bewildered by the announcement. I personally had a large important Silverlight 5 app in production use, and I knew other developers who, like me, had invested enormous amounts of time and effort in the Silverlight platform. The anger turned red hot when we discovered that there was no replacement of any form for Silverlight. Microsoft hinted that everyone should use HTML5 (HTML, JavaScript and CSS) to write replacement apps.
Silverlight ran the .NET CLR inside a web browser plug-in, so (subject to certain constraints) you could write complex business logic and render a rich UI using a subset of the controls, styles and transforms available in WPF desktop programs. With Silverlight it was possible to create rich responsive business apps and run them in the web browser. So to suggest that apps like that could be replaced with HTML5 was both insulting and preposterous.
HTML, JavaScript and CSS are just too primitive to create serious business apps. I have personally been driven to near insanity or breakdown trying to cobble together a stable, attractive, friendly or performant app in HTML5. There are lots of expensive toolkits of controls and components available from major vendors to supposedly help, but they usually stuff your code and UI with millions of lines of JavaScript and CSS styles nested to incomprehensible depths.
The recent arrival of Blazor makes writing HTML5 apps slightly less painful, but in the end you are still at the mercy of rendering your UI in the browser using dumb HTML, scripting and styles.
So here we are in the distant science fiction future of 2022 and there is still no way of writing rich and reliable business apps in the web browser.
In April 2022 I used Visual Studio 2015 (in a VM) to open my Silverlight hobby apps projects to take screenshots of them for posterity. Internet Explorer 11 issued security warning prompts, but luckily the apps did load and run. The screenshots can be seen here: Boxes, Hypno Balls, Prime Spiral and Random Shapes.
At this point I realise that Silverlight is completely DEAD and BURIED. It's rung down the curtain and joined the choir invisible. It's an ex-platform (with apologies to Monty Python).
I've flagged my Silverlight hobby project repositories as archived and I've moved the project files to an archive folder.
For more information on related topics see: I'm in the future of the web and it doesn't work.
Subscribe to:
Posts (Atom)